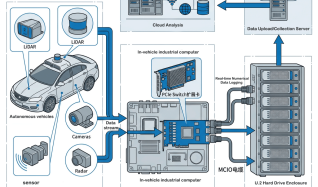
AI大規模モデルトレーニング、ハイパフォーマンスコンピューティング、クラウドコンピューティングの急速な発展に伴い、企業のサーバーGPUコンピューティングパワーとストレージ性能に対する需要は爆発的な成長傾向を示している。しかし、従来のサーバー・アーキテクチャには、PCIeスロットの制限、GPUとSSDの配備バランスの難しさ、拡張ソリューションの柔軟性の欠如など、拡張機能に多くのボトルネックがあります。これらの問題は、ビジネスの革新を大きく制限してきた。本稿では、こうした業界のペインポイントを深く分析し、LR-LINK LRSV9500-4I は、柔軟なX4/X8/X16分岐モードにより、企業にワンストップの拡張ソリューションを提供します。
I.PCIeスロットリソースの深刻な不足
1.1 現在の状況
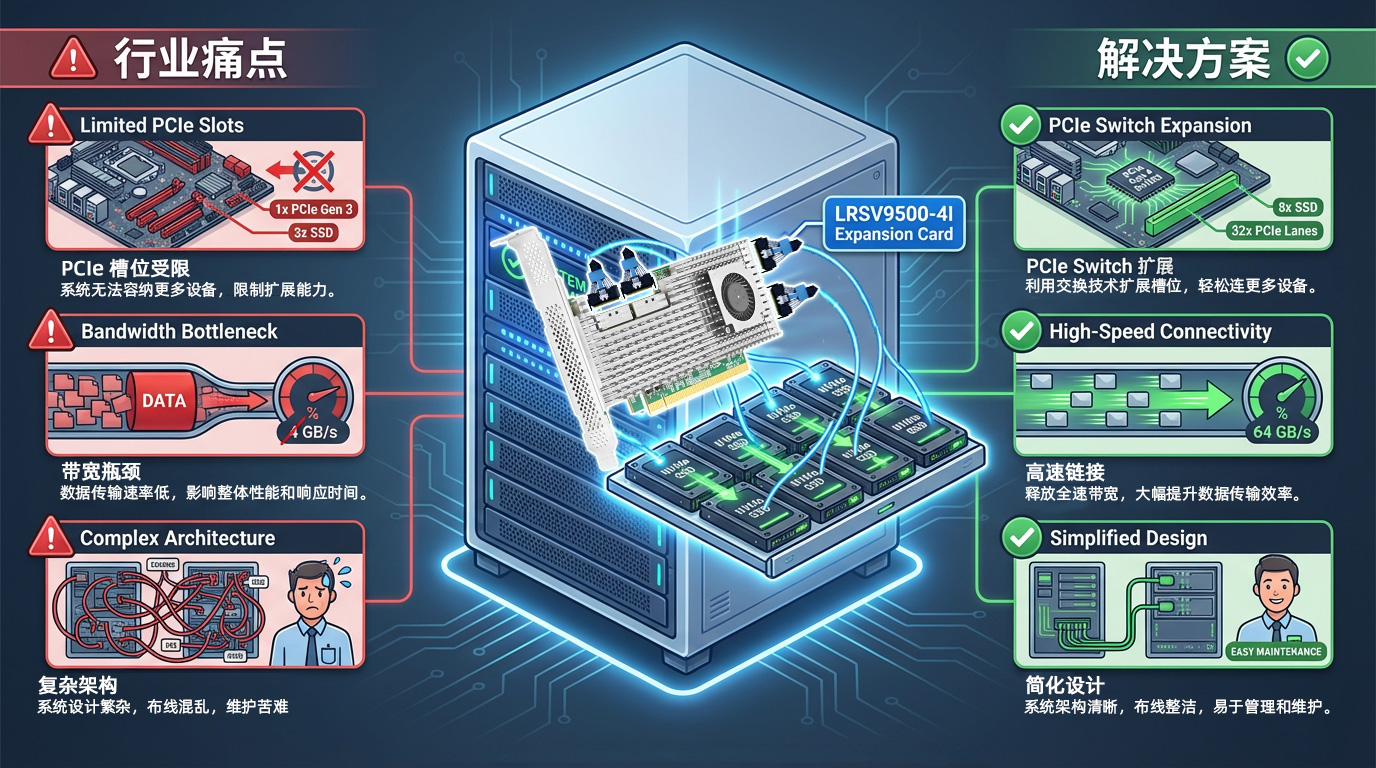
最新のサーバー用マザーボードは通常、4~8個のPCIeスロットしか備えておらず、ネットワークカード、GPU、NVMe SSD、RAIDカードなど、さまざまな周辺機器の要件を同時に満たす必要がある。AIトレーニングのシナリオでは、1台のサーバーに4~8枚のGPUグラフィックス・カードと高速ストレージ・デバイスが必要になることがあり、PCIeスロットの数が最大の制約になることがよくあります。
1.2 ビジネスへの影響
GPUとSSDを同時に導入するのは難しく、コンピューティングパワーとストレージの間でトレードオフを行う必要がある。
企業はより多くのサーバーを購入しなければならず、TCOの大幅な増加につながる。
キャビネットのスペースが急速に枯渇し、データセンターのリソース利用率が低くなる。
1.3 LRSV9500-4I ソリューション
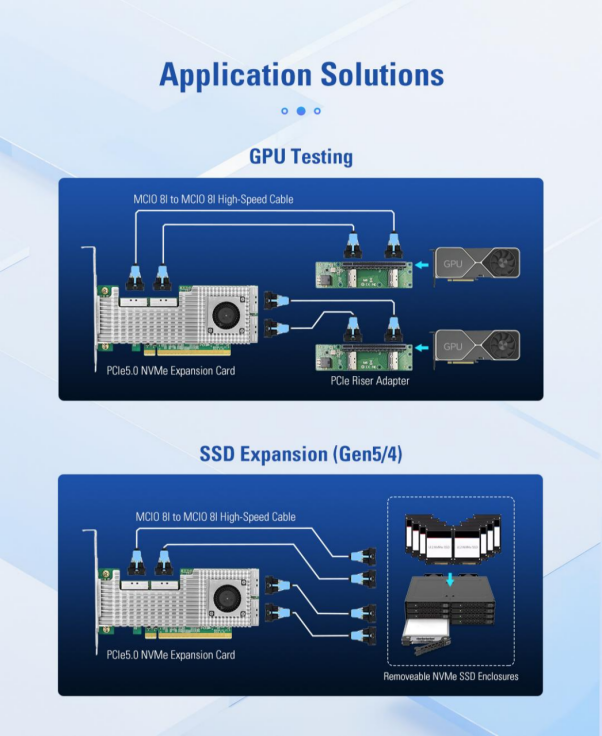
Broadcom PEX89048 PCIeスイッチチップをベースにしたLRSV9500-4Iは、単一のPCIe GEN 5.0 x16スロットを4つのMCIO 8Iインターフェースに拡張します。X4モードで8台のNVMe SSD、X16モードで2枚のハイエンドGPUグラフィックスカードを接続できます。PCIeスロットが1つしか占有されないため、拡張効率が800%向上します。
AIのトレーニングシナリオでは、GPUと高速ストレージの両方に対して極めて高い要件が求められる。GPUは大量のデータを処理する必要があるが、従来のSAS/SATAストレージの帯域幅とIOPSではその需要を満たすことができない。しかし、マザーボード上のPCIeスロットがGPUで占有された後では、NVMe SSDアレイを展開するための十分なインターフェイスがありません。
· 大規模モデルのトレーニングでは、GPUコンピューティングパワーの利用率はピーク時のコンピューティングパワーよりも低くなるのが普通です。例えば、1000GPUクラスタの利用率は約59%、10000GPUクラスタの利用率は約55.2%です。
· トレーニングデータの読み込みが制限要因となり、モデルの反復サイクルが長くなる
X8ハイブリッドモードにより、LRSV9500-4IはGPUとNVMe SSDの両方を同時にサポートすることができます。例えば、2×X8はGPUの接続に使用され、残りの2×X8はローカルキャッシュとして2台のNVMe SSDに接続されます。こうすることで、GPUは高速ローカルストレージから直接データを読み出すことができ、トレーニング効率が3~5倍向上します。
PCIe 5.0規格の信号速度は32GT/秒に達する。この倍速は、データ伝送の正確性と効率を保証するシグナルインテグリティに対する極めて厳しい要件を意味する。長距離伝送、粗悪なケーブルやコネクタは、信号の減衰やビットエラーレートの上昇を招き、深刻なケースでは機器の識別ができなくなったり、頻繁に切断されたりします。
· GPUトレーニングの過程で、カードが切断されると、数日分の計算結果が失われる。
· ストレージデバイスは、PCIe 5.0から4.0、あるいは3.0へと速度を落として動作する。
· システムが不安定になり、ブルースクリーンが発生し、事業継続に影響が出る。
LRSV9500-4IはハイスペックPCB設計、高品質コネクタ、信号最適化技術を採用し、PCIe 5.0のフルレート安定動作を保証します。PCIe 5.0技術は最大14,000MB/秒のシーケンシャルリードとライトスピードを提供し、適切な構成で最適なパフォーマンスを発揮します。MCIOインターフェイスは信頼性の高い物理的接続を提供し、認証されたケーブルを使用することで、ビットエラーレートを効果的に低減し、7×24時間の安定した動作を保証します。
マルチGPUトレーニングシナリオでは、GPU間の相互接続トポロジーがトレーニング効率に直接影響します。従来のソリューションでは、CPUが提供するPCIeチャネルに依存しており、複数のカード間の通信はCPUを経由する必要があるため、帯域幅が制限され、レイテンシが高くなります。
· GPU間の通信帯域が十分でないため、分散トレーニングの効率は低い
· 大規模なクラスター拡大には困難が伴う
X16モードでは、LRSV9500-4Iはスイッチを通してGPUの効率的なP2P通信を可能にし、マルチカードトレーニングの効率を効果的に向上させます。
クロスホストクラスターでは、RoCE v2(RDMA over Converged Ethernet)をサポートするネットワークカードの助けを借りて、GPUはCPUをバイパスし、ネットワークアダプタを介してリモートGPUのビデオメモリに直接データを書き込むことができます。複数のサーバーを直接相互接続し、メモリ共有と高速データ交換を実現します。
サーバーGPUとストレージの拡張における悩みは、基本的に限られたリソースと無限の需要との矛盾です。PCIeスイッチ技術と柔軟なX4/X8/X16分岐モードにより、LRSV9500-4Iは企業に効率的なソリューションパスを提供します。AIトレーニング、ハイパフォーマンスコンピューティング、ビッグデータ分析、ビデオ制作など、用途はさまざまです、 LRSV9500-4I は、優れた拡張能力と投資保護を提供することができる。
PCIe5.0分野におけるLR-LINKのフラッグシップ製品であるLRSV9500-4Iは、Broadcom PEX89048チップの優れた性能と完璧なエコシステムのサポートにより、AIサーバーやデータセンター構築のための拡張ソリューションとして選ばれつつあります。LRSV9500-4Iを選択することは、柔軟かつ効率的で未来志向の拡張アーキテクチャを選択することを意味します。