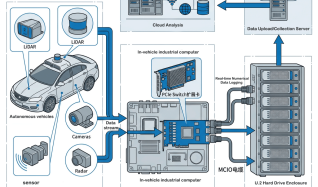




AI 대규모 모델 학습, 고성능 컴퓨팅 및 클라우드 컴퓨팅의 급속한 발전으로 서버 GPU 컴퓨팅 성능과 스토리지 성능에 대한 기업의 수요는 폭발적인 성장세를 보이고 있습니다. 그러나 기존 서버 아키텍처는 제한된 PCIe 슬롯, GPU와 SSD 배치의 균형 잡기 어려움, 확장 솔루션의 유연성 부족 등 확장 기능에 많은 병목 현상이 있습니다. 이러한 문제들은 비즈니스 혁신을 심각하게 제한해 왔습니다. 이 백서에서는 이러한 업계의 문제점을 심층적으로 분석하고 LR-LINK가 어떻게 이러한 문제를 해결할 수 있는지 보여줍니다. LRSV9500-4I 는 유연한 X4/X8/X16 분기 모드를 통해 기업에게 원스톱 확장 솔루션을 제공합니다.
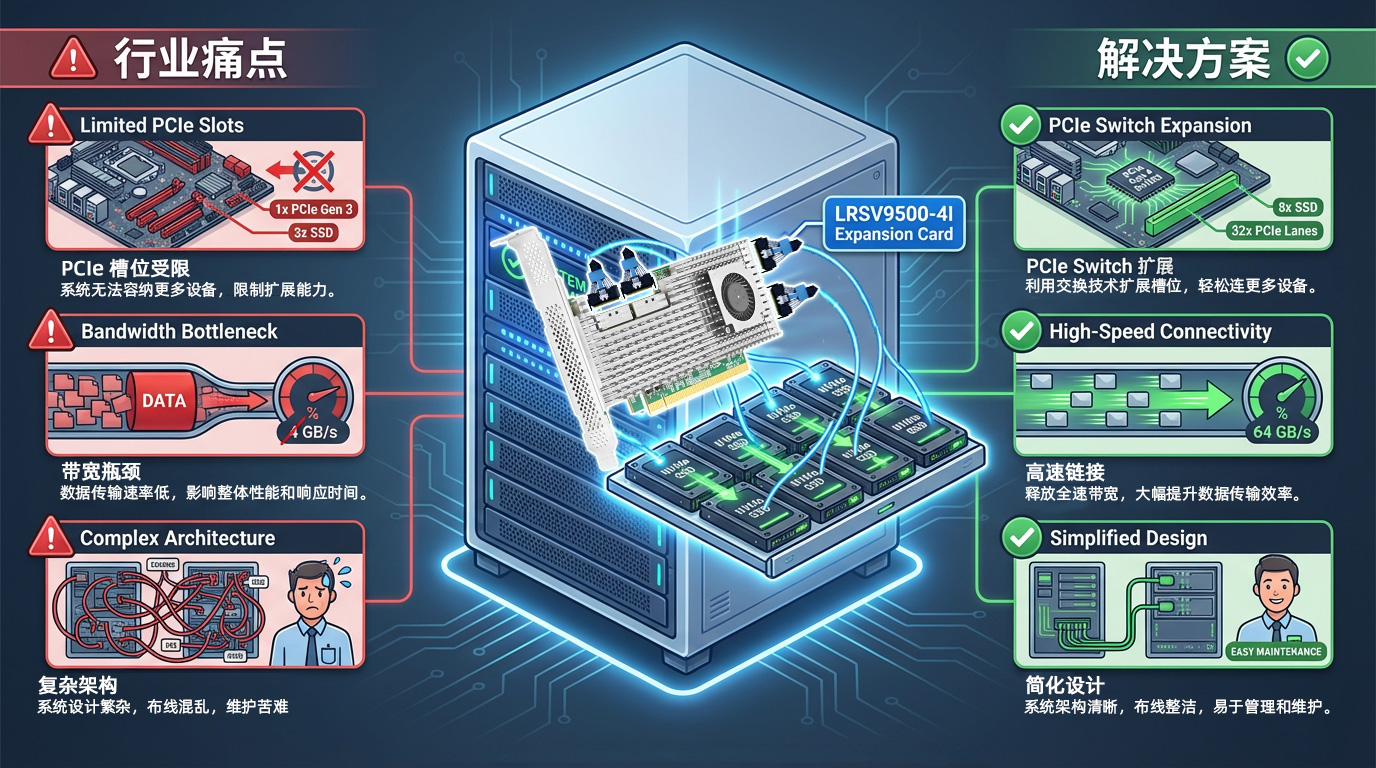
I. 심각한 PCIe 슬롯 리소스 부족
1.1 현재 상황
최신 서버 마더보드는 일반적으로 4~8개의 PCIe 슬롯만 제공하기 때문에 네트워크 카드, GPU, NVMe SSD, RAID 카드 등 다양한 주변기기의 요구 사항을 동시에 충족해야 합니다. AI 학습 시나리오에서는 단일 서버에 4~8개의 GPU 그래픽 카드와 고속 저장 장치가 필요할 수 있으므로 PCIe 슬롯 수가 가장 큰 제약이 될 수 있습니다.
1.2 비즈니스에 미치는 영향
GPU와 SSD를 동시에 배포하는 것은 어렵고, 컴퓨팅 성능과 스토리지 간에 절충점을 찾아야 합니다.
기업은 더 많은 서버를 구매해야 하므로 TCO가 크게 증가합니다.
캐비닛 공간이 빠르게 고갈되어 데이터 센터의 리소스 활용도가 낮아집니다.
1.3 LRSV9500-4I 솔루션
브로드컴 PEX89048 PCIe 스위치 칩을 기반으로 하는 LRSV9500-4I는 단일 PCIe GEN 5.0 x16 슬롯을 4개의 MCIO 8I 인터페이스로 확장합니다. X4 모드에서는 8개의 NVMe SSD를 연결할 수 있고, X16 모드에서는 2개의 하이엔드 GPU 그래픽 카드를 연결할 수 있습니다. 하나의 PCIe 슬롯만 사용하므로 확장 효율성이 800% 향상됩니다.
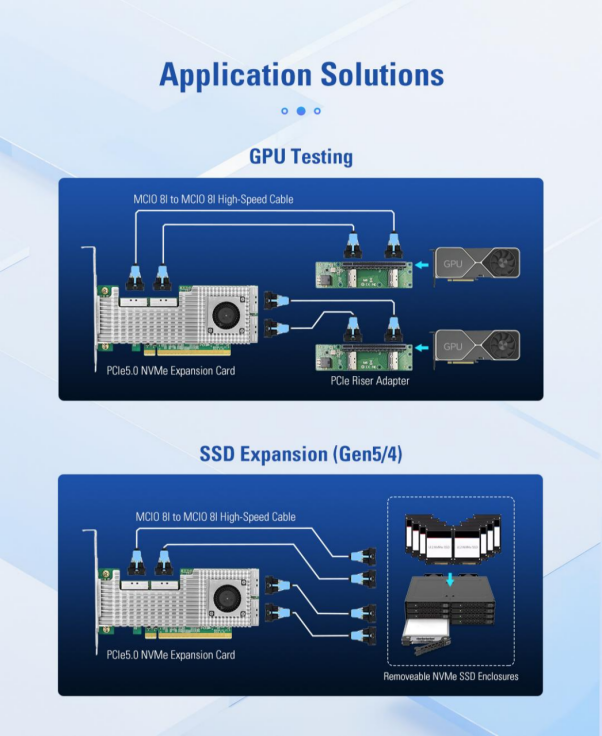
AI 학습 시나리오는 GPU와 고속 스토리지 모두에 대한 요구 사항이 매우 높습니다. GPU는 방대한 양의 데이터를 처리해야 하지만, 기존 SAS/SATA 스토리지의 대역폭과 IOPS는 이러한 수요를 충족할 수 없습니다. 그러나 마더보드의 PCIe 슬롯을 GPU가 차지하고 나면 NVMe SSD 어레이를 배포할 인터페이스가 충분하지 않습니다.
· 대규모 모델 훈련 중에는 일반적으로 GPU 컴퓨팅 파워 사용률이 최대 컴퓨팅 파워보다 낮습니다. 예를 들어, 사용률은 1000-GPU 클러스터에서는 약 59%, 10000-GPU 클러스터에서는 약 55.2%입니다.
· 학습 데이터 읽기가 제한적인 요소가 되어 모델 반복 주기가 길어집니다.
X8 하이브리드 모드를 통해 LRSV9500-4I는 GPU와 NVMe SSD를 동시에 지원할 수 있습니다. 예를 들어, 2×X8은 GPU 연결에 사용되며 나머지 2×X8은 로컬 캐시로 2개의 NVMe SSD에 연결됩니다. 이러한 방식으로 GPU는 고속 로컬 스토리지에서 직접 데이터를 읽을 수 있어 트레이닝 효율이 3~5배 향상됩니다.
PCIe 5.0 표준의 신호 속도는 32GT/s에 이릅니다. 이 두 배의 속도는 데이터 전송의 정확성과 효율성을 보장하기 위해 신호 무결성에 대한 매우 엄격한 요구 사항을 의미합니다. 장거리 전송, 열악한 케이블 또는 커넥터는 신호 감쇠와 비트 오류율 증가로 이어지며 심한 경우 장비를 식별할 수 없거나 자주 연결이 끊어집니다.
· GPU 트레이닝 과정에서 카드의 연결이 끊어지면 며칠 동안의 컴퓨팅 결과가 손실됩니다.
· 스토리지 장치는 PCIe 5.0에서 4.0 또는 심지어 3.0까지 낮은 속도로 실행됩니다.
· 시스템 불안정 및 죽음의 블루스크린이 발생하여 비즈니스 연속성에 영향을 미칩니다.
LRSV9500-4I는 고사양 PCB 설계, 고품질 커넥터 및 신호 최적화 기술을 채택하여 PCIe 5.0이 최대 속도에서 안정적으로 작동하도록 보장합니다. PCIe 5.0 기술은 올바른 구성에서 최대 14,000MB/s의 순차 읽기 및 쓰기 속도와 최적의 성능을 제공할 수 있습니다. MCIO 인터페이스는 안정적인 물리적 연결을 제공하며, 인증된 케이블을 사용하면 비트 오류율을 효과적으로 줄이고 7×24시간 안정적인 작동을 보장할 수 있습니다.
멀티 GPU 트레이닝 시나리오에서는 GPU 간의 상호 연결 토폴로지가 트레이닝 효율성에 직접적인 영향을 미칩니다. 기존 솔루션은 CPU가 제공하는 PCIe 채널에 의존하며, 여러 카드 간의 통신은 CPU를 거쳐야 하므로 대역폭이 제한되고 지연 시간이 길어집니다.
· GPU 간 통신 대역폭이 부족하여 분산 훈련의 효율성이 낮습니다.
· 대규모 클러스터 확장 시 발생하는 어려움
X16 모드에서 LRSV9500-4I는 GPU가 스위치를 통해 효율적인 P2P 통신을 할 수 있도록 하여 멀티 카드 트레이닝의 효율성을 효과적으로 개선합니다.
크로스 호스트 클러스터의 경우, RoCE v2(RDMA over Converged Ethernet)를 지원하는 네트워크 카드의 도움으로 GPU는 CPU를 우회하여 네트워크 어댑터를 통해 원격 GPU의 비디오 메모리에 직접 데이터를 쓸 수 있습니다. 여러 서버가 직접 상호 연결되어 메모리 공유 및 고속 데이터 교환이 가능합니다.
서버 GPU 및 스토리지 확장의 어려움은 본질적으로 제한된 리소스와 무한한 수요 사이의 모순입니다. PCIe 스위치 기술과 유연한 X4/X8/X16 분기 모드를 통해 LRSV9500-4I는 기업에게 효율적인 솔루션 경로를 제공합니다. AI 트레이닝, 고성능 컴퓨팅, 빅데이터 분석, 비디오 제작 등 다양한 분야에 적합합니다, LRSV9500-4I 는 뛰어난 확장 기능과 투자 보호 기능을 제공합니다.
PCIe 5.0 분야의 LR-LINK의 주력 제품인 LRSV9500-4I는 브로드컴 PEX89048 칩의 선도적인 성능과 완벽한 에코시스템 지원을 바탕으로 AI 서버 및 데이터 센터 구축에 선호되는 확장 솔루션이 되고 있습니다. LRSV9500-4I를 선택한다는 것은 유연하고 효율적이며 미래 지향적인 확장 아키텍처를 선택한다는 것을 의미합니다.






