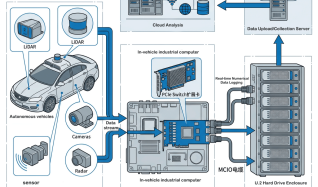




مع التطور السريع لتدريب النماذج الكبيرة للذكاء الاصطناعي والحوسبة عالية الأداء والحوسبة السحابية، أظهر طلب الشركات على قوة حوسبة وحدة معالجة الرسومات للخوادم وأداء التخزين اتجاهاً هائلاً للنمو. ومع ذلك، تعاني بنيات الخوادم التقليدية من العديد من العوائق في قدرات التوسع، مثل محدودية فتحات PCIe، وصعوبة الموازنة بين نشر وحدة معالجة الرسومات ووحدة تخزين أقراص الحالة الصلبة (SSD)، ونقص المرونة في حلول التوسعة. وقد أدت هذه المشاكل إلى تقييد الابتكار في مجال الأعمال بشدة. ستحلل هذه الورقة البحثية بعمق هذه المشاكل في هذا المجال وتوضح كيف أن LR-LINK LRSV9500-4I يوفر للمؤسسات حلاً شاملاً للتوسعة من خلال أوضاع التشعب X4/X8/X16 المرنة.
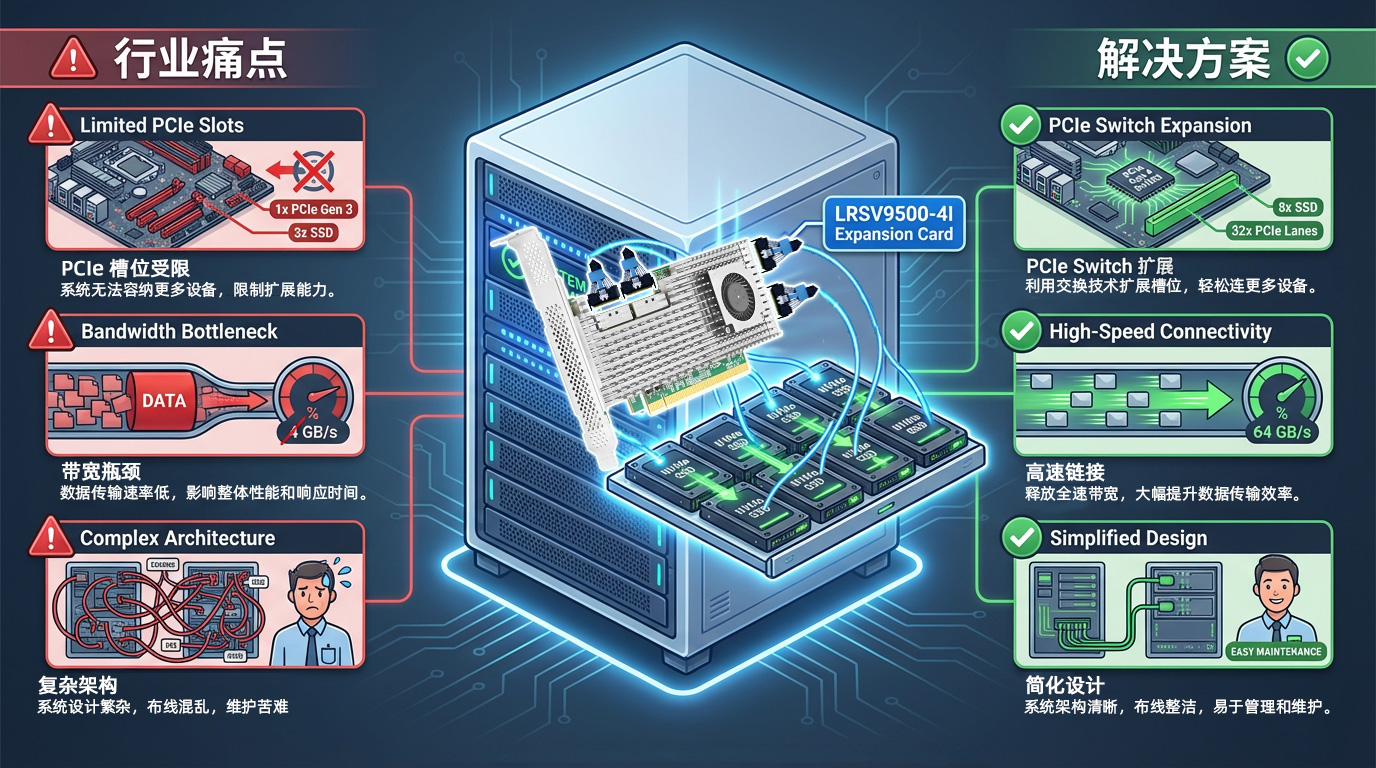
I. النقص الحاد في موارد فتحات PCIe
1.1 الوضع الحالي
عادةً ما توفر اللوحات الأم للخوادم الحديثة من 4 إلى 8 فتحات PCIe فقط، والتي تحتاج إلى تلبية متطلبات الأجهزة الطرفية المختلفة مثل بطاقات الشبكة ووحدات معالجة الرسومات ووحدات معالجة الرسومات ومحركات أقراص NVMe SSD وبطاقات RAID في نفس الوقت. في سيناريوهات التدريب على الذكاء الاصطناعي، قد يتطلب الخادم الواحد من 4 إلى 8 بطاقات رسومات لوحدة معالجة الرسومات GPU، بالإضافة إلى أجهزة تخزين عالية السرعة، مما يجعل عدد فتحات PCIe غالباً ما يكون أكبر عائق.
1.2 الآثار المترتبة على الأعمال التجارية
من الصعب نشر وحدة معالجة الرسومات (GPU) ومحرك أقراص الحالة الصلبة (SSD) في نفس الوقت، ويجب إجراء مفاضلات بين قوة الحوسبة والتخزين
تضطر الشركات إلى شراء المزيد من الخوادم، مما يؤدي إلى زيادة كبيرة في التكلفة الإجمالية للملكية
استنفاد مساحة الخزانة بسرعة، مما يؤدي إلى انخفاض استخدام الموارد في مراكز البيانات
1.3 محلول LRSV9500-4I
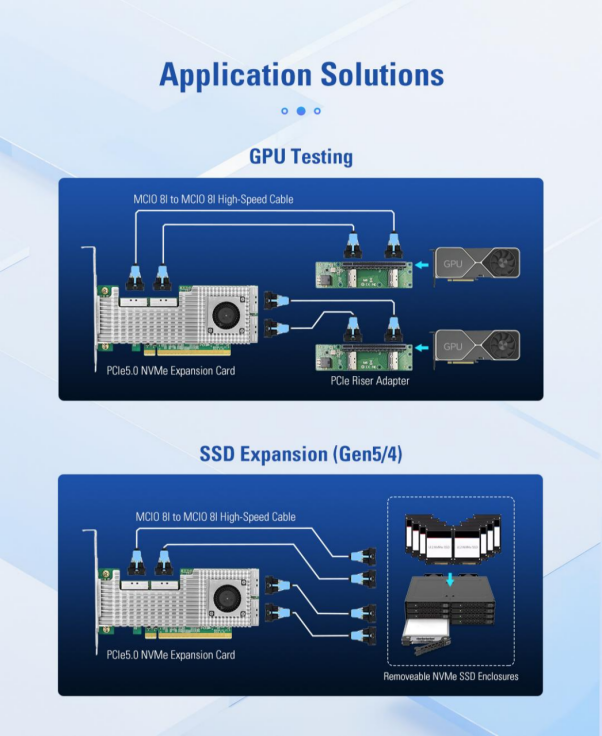
استنادًا إلى شريحة Broadcom PEX89048 PCIe Switch PEX89048، تعمل شريحة LRSV9500-4I على توسيع فتحة PCIe GEN 5.0 x16 واحدة من الفئة 5.0 إلى 4 واجهات MCIO 8I. ويمكنها توصيل 8 محركات أقراص NVMe SSD في وضع X4 وبطاقتي رسومات GPU متطورة في وضع X16. يتم شغل فتحة PCIe واحدة فقط، مما يحقق تحسناً بنسبة 800% في كفاءة التوسعة.
تتطلب سيناريوهات تدريب الذكاء الاصطناعي متطلبات عالية للغاية لكل من وحدة معالجة الرسومات والتخزين عالي السرعة. تحتاج وحدات معالجة الرسومات إلى معالجة كميات هائلة من البيانات، في حين أن عرض النطاق الترددي و IOPS للتخزين التقليدي SAS/SATA لا يمكن أن يلبي الطلب. ومع ذلك، بعد شغل فتحات PCIe على اللوحة الأم بوحدات معالجة الرسومات، لا توجد واجهات كافية لنشر مصفوفات NVMe SSD.
· أثناء التدريب على النماذج الكبيرة، عادةً ما يكون معدل استخدام طاقة حوسبة وحدة معالجة الرسومات أقل من ذروة طاقة الحوسبة. على سبيل المثال، يبلغ معدل الاستخدام حوالي 59% في مجموعة وحدات معالجة الرسومات ذات 1000 وحدة معالجة رسومية وحوالي 55.2% في مجموعة وحدات معالجة الرسومات ذات 10000 وحدة معالجة رسومية.
· تصبح قراءة بيانات التدريب عاملاً مقيداً، مما يؤدي إلى دورات تكرار أطول للنموذج
من خلال الوضع الهجين X8 الهجين، يمكن لوحدة معالجة الرسومات LRSV9500-4I دعم كل من وحدة معالجة الرسومات ومحرك أقراص NVMe SSD في الوقت نفسه. على سبيل المثال، يتم استخدام 2 × X8 لتوصيل وحدات معالجة الرسومات، ويتم توصيل 2 × X8 المتبقية بوحدتي تخزين NVMe SSD كذاكرة تخزين مؤقت محلية. وبهذه الطريقة، يمكن لوحدات معالجة الرسومات قراءة البيانات مباشرةً من وحدة تخزين محلية عالية السرعة، مما يحسن كفاءة التدريب بمقدار 3 إلى 5 مرات.
يصل معدل إشارة معيار PCIe 5.0 إلى 32GT/s. هذه السرعة المضاعفة تعني متطلبات صارمة للغاية لسلامة الإشارة لضمان دقة وكفاءة نقل البيانات. سيؤدي الإرسال لمسافات طويلة أو الكابلات أو الموصلات الرديئة إلى توهين الإشارة وزيادة معدل الخطأ في البت، وفي الحالات الشديدة لا يمكن تحديد المعدات أو فصلها بشكل متكرر.
· في عملية تدريب وحدة معالجة الرسومات، إذا تم فصل البطاقة، فستفقد أيام من نتائج الحوسبة
· تعمل أجهزة التخزين بسرعة مخفضة، من PCIe 5.0 إلى 4.0، أو حتى 3.0
· يحدث عدم استقرار النظام وشاشة الموت الزرقاء، مما يؤثر على استمرارية العمل
تعتمد LRSV9500-4I على تصميم ثنائي الفينيل متعدد الكلور عالي المواصفات وموصلات عالية الجودة وتقنية تحسين الإشارة لضمان التشغيل المستقر لـ PCIe 5.0 بمعدل كامل. يمكن لتقنية PCIe 5.0 توفير سرعات قراءة وكتابة متسلسلة تصل إلى 14000 ميجابايت/ثانية وأداء مثالي في ظل التكوين الصحيح. توفر واجهة MCIO اتصالاً ماديًا موثوقًا به، ومع الكابلات المعتمدة، يمكنها تقليل معدل خطأ البت بشكل فعال وضمان التشغيل المستقر على مدار 7 × 24 ساعة.
في سيناريوهات التدريب على وحدات معالجة الرسومات المتعددة، تؤثر طوبولوجيا التوصيل البيني بين وحدات معالجة الرسومات بشكل مباشر على كفاءة التدريب. وتعتمد الحلول التقليدية على قنوات PCIe التي توفرها وحدة المعالجة المركزية، ويجب أن يمر الاتصال بين البطاقات المتعددة عبر وحدة المعالجة المركزية، مما يؤدي إلى عرض نطاق ترددي محدود وزمن انتقال عالٍ.
· كفاءة التدريب الموزع منخفضة بسبب عدم كفاية عرض نطاق الاتصال بين وحدات معالجة الرسومات
· تتم مواجهة صعوبات في التوسع العنقودي على نطاق واسع
في وضع X16، تُمكِّن LRSV9500-4I وحدات معالجة الرسومات من تحقيق اتصال P2P فعال من خلال المحول، مما يحسن كفاءة التدريب متعدد البطاقات بشكل فعال.
بالنسبة للمجموعات المشتركة بين المضيفين، بمساعدة بطاقات الشبكة التي تدعم RoCE v2 (RDMA عبر الإيثرنت المتقارب)، يمكن لوحدات معالجة الرسومات تجاوز وحدة المعالجة المركزية وكتابة البيانات مباشرةً إلى ذاكرة الفيديو لوحدات معالجة الرسومات البعيدة من خلال محول الشبكة. يتم ربط خوادم متعددة بشكل مباشر لتحقيق مشاركة الذاكرة وتبادل البيانات بسرعة عالية.
تتمثل نقاط الألم في وحدة معالجة الرسومات للخادم وتوسيع التخزين بشكل أساسي في التناقض بين الموارد المحدودة والطلب غير المحدود. من خلال تقنية PCIe Switch وأوضاع التشعب المرنة X4/X8/X16، يوفر LRSV9500-4I للمؤسسات مسار حل فعال. سواء للتدريب على الذكاء الاصطناعي أو الحوسبة عالية الأداء أو تحليل البيانات الضخمة أو إنتاج الفيديو, LRSV9500-4I يمكن أن توفر قدرات توسع ممتازة وحماية ممتازة للاستثمار.
وباعتباره المنتج الرئيسي لشركة LR-LINK في مجال PCIe 5.0، أصبح LRSV9500-4I، الذي يعتمد على الأداء الرائد لشريحة Broadcom PEX89048 والدعم المثالي للنظام البيئي، حل التوسعة المفضل لخادم الذكاء الاصطناعي وبناء مركز البيانات. إن اختيار LRSV9500-4I يعني اختيار بنية توسعة مرنة وفعالة وموجهة نحو المستقبل.






